Stata 17 là phần mềm thống kê mang đến một loạt các tính năng và cải tiến mới để trao quyền cho các nhà phân tích và nghiên cứu dữ liệu. Trong bài viết này, chúng ta sẽ khám phá những bổ sung thú vị cho Stata 17 ngay bên dưới nhé.
Bảng tùy chỉnh trong Stata 17
Một trong những tính năng nổi bật của Stata 17 là giới thiệu các bảng có thể tùy chỉnh. Với chức năng mới này, người dùng có quyền kiểm soát tốt hơn đối với hình thức và bố cục bảng của họ. Bạn có thể dễ dàng tùy chỉnh tiêu đề, chú thích cuối trang, định dạng ô và thậm chí thêm bảng phối màu để nâng cao khả năng trình bày trực quan dữ liệu của mình. Tính linh hoạt này cho phép truyền đạt kết quả hiệu quả hơn và giúp dễ dàng tạo các bảng sẵn sàng xuất bản trực tiếp từ Stata.
Kinh tế lượng Bayes
Stata 17 giới thiệu một bộ công cụ kinh tế lượng Bayes toàn diện, mở ra những khả năng mới để phân tích các mô hình kinh tế phức tạp. Kinh tế lượng Bayesian tận dụng sức mạnh của thống kê Bayesian để ước tính các tham số và đưa ra dự đoán dựa trên kiến thức trước đó và dữ liệu quan sát được.
Với khả năng kinh tế lượng Bayesian của Stata, giờ đây bạn có thể ước tính các mô hình như Bayesian VAR (Vector Autoregressive), đa cấp độ Bayesian và dự báo động Bayesian, cùng các mô hình khác. Những công cụ này cung cấp cho các nhà nghiên cứu một khuôn khổ mạnh mẽ hơn để phân tích kinh tế và ra quyết định.
PyStata: Tích hợp Python và Stata
Stata 17 giới thiệu PyStata, một sự tích hợp mạnh mẽ giữa Python và Stata. Sự tích hợp này cho phép người dùng kết hợp liền mạch các điểm mạnh của cả hai ngôn ngữ và tận dụng các thư viện mở rộng có sẵn trong Python.
Với PyStata, bạn có thể dễ dàng gọi các lệnh Stata từ bên trong tập lệnh Python, chuyển dữ liệu qua lại giữa hai môi trường và tận dụng khả năng trực quan hóa và thao tác dữ liệu của Python. Sự tích hợp này nâng cao tính linh hoạt và khả năng mở rộng của Stata, cho phép người dùng khai thác toàn bộ tiềm năng của cả hai ngôn ngữ trong quy trình phân tích của họ.
Hỗ trợ Jupyter Notebook
Ngoài việc tích hợp Python, Stata 17 hiện hỗ trợ Jupyter Notebook, một môi trường điện toán tương tác dựa trên web phổ biến. Jupyter Notebook cung cấp giao diện thân thiện với người dùng để phân tích và trực quan hóa dữ liệu, khiến nó trở thành nền tảng lý tưởng cho các nhà nghiên cứu và phân tích.
Với sự tích hợp của Stata vào Jupyter Notebook, bạn có thể kết hợp liền mạch mã Stata, đầu ra và văn bản giải thích trong một tài liệu. Sự tích hợp này nâng cao khả năng tái sản xuất và cộng tác, cho phép người dùng chia sẻ các phân tích và phát hiện của họ hiệu quả hơn.
Mô hình khác biệt trong khác biệt (DID)
Stata 17 giới thiệu các công cụ tiên tiến để ước tính các mô hình Sự khác biệt trong Sự khác biệt (DID), một kỹ thuật kinh tế lượng được sử dụng rộng rãi để suy luận nhân quả. Các mô hình DID đặc biệt hữu ích trong việc đánh giá tác động của các biện pháp can thiệp hoặc điều trị bằng chính sách bằng cách so sánh những thay đổi về kết quả trước và sau can thiệp, đối với cả nhóm can thiệp và nhóm kiểm soát.
Với các khả năng mới của Stata, việc ước tính và giải thích các mô hình DID trở nên đơn giản hơn, trao quyền cho các nhà nghiên cứu đưa ra kết luận nhân quả mạnh mẽ từ dữ liệu của họ.
Stata nhanh hơn
Cải thiện hiệu suất là điểm nổi bật chính của Stata 17. Phiên bản mới nhất đi kèm với tốc độ và hiệu quả được nâng cao, đảm bảo rằng các phân tích của bạn thậm chí còn chạy nhanh hơn.
Cho dù bạn đang làm việc với các tập dữ liệu lớn, thực hiện các quy trình thống kê phức tạp hay chạy mô phỏng, các thuật toán được tối ưu hóa và khả năng xử lý song song của Stata 17 sẽ giúp giảm đáng kể thời gian tính toán. Những cải tiến hiệu suất này giúp tăng năng suất và cho phép các nhà nghiên cứu tập trung hơn vào việc giải thích và phân tích dữ liệu.
Các mô hình Cox được kiểm duyệt theo khoảng thời gian
Phân tích tỷ lệ sống sót là một công cụ quan trọng trong nghiên cứu y học, khoa học xã hội và nhiều lĩnh vực khác. Stata 17 giới thiệu các mô hình Cox được kiểm duyệt theo khoảng thời gian, mở rộng phạm vi các kỹ thuật phân tích khả năng sống còn cho người dùng.
Dữ liệu bị kiểm duyệt theo khoảng thời gian xảy ra khi sự kiện quan tâm chỉ được biết là đã xảy ra trong một phạm vi nhất định. Các khả năng mới trong Stata cho phép ước tính các mô hình mối nguy theo tỷ lệ Cox với dữ liệu được kiểm duyệt theo khoảng thời gian, cho phép các nhà nghiên cứu rút ra những hiểu biết chính xác hơn từ phân tích tỷ lệ sống sót của họ.
Phân tích tổng hợp đa biến
Phân tích tổng hợp là một kỹ thuật thống kê mạnh mẽ kết hợp kết quả từ nhiều nghiên cứu để có được ước tính chính xác hơn về quy mô hiệu ứng. Stata 17 tăng cường khả năng phân tích tổng hợp bằng cách giới thiệu phân tích tổng hợp đa biến.
Các phương pháp phân tích tổng hợp truyền thống giả định sự độc lập giữa các kết quả, nhưng phân tích tổng hợp đa biến tính đến mối tương quan giữa nhiều kết quả trong một nghiên cứu. Tiến bộ này cho phép các nhà nghiên cứu tiến hành phân tích toàn diện hơn và hiểu sâu hơn từ các nghiên cứu phân tích tổng hợp.
Mô hình VAR Bayesian
Các mô hình tự hồi quy véc tơ (VAR) được sử dụng rộng rãi trong kinh tế lượng để phân tích các mối quan hệ động giữa nhiều biến chuỗi thời gian. Stata 17 giới thiệu các mô hình Bayesian VAR, cung cấp một cách tiếp cận linh hoạt và mạnh mẽ để lập mô hình dữ liệu chuỗi thời gian.
Các mô hình VAR Bayesian cho phép đưa vào thông tin trước đó và ước tính độ không đảm bảo trong các tham số, mang lại kết quả đáng tin cậy hơn so với các phương pháp tiếp cận thường xuyên truyền thống. Các mô hình này đặc biệt có giá trị khi xử lý các cỡ mẫu nhỏ hoặc khi có sẵn kiến thức trước đó.
Mô hình đa cấp Bayesian
Mô hình đa cấp, còn được gọi là mô hình phân cấp hoặc hiệu ứng hỗn hợp, thường được sử dụng để phân tích dữ liệu có cấu trúc hoặc phân cấp lồng nhau. Stata 17 giới thiệu mô hình đa cấp Bayes, kết hợp tính linh hoạt và sức mạnh của mô hình đa cấp với những lợi thế của suy luận Bayes.
Các mô hình đa cấp độ Bayes cho phép ước tính cả hiệu ứng cố định và ngẫu nhiên, kết hợp kiến thức trước đó và tính đến sự không chắc chắn trong các tham số của mô hình. Sự tích hợp này cung cấp cho các nhà nghiên cứu một khung toàn diện hơn để phân tích các cấu trúc dữ liệu phân cấp phức tạp.

Ước tính hiệu quả điều trị bằng Lasso
Lasso hiệu ứng điều trị là một công cụ mạnh mẽ để ước tính hiệu quả điều trị trong các nghiên cứu quan sát, đặc biệt khi xử lý các đồng biến số chiều cao. Stata 17 giới thiệu ước tính bằng dây thòng lọng về tác động điều trị, cho phép các nhà nghiên cứu ước tính các tác động nhân quả trong khi tự động chọn các biến đồng thời có liên quan và giải quyết vấn đề xác định sai mô hình.
Tính năng mới này cho phép người dùng tiến hành suy luận nhân quả chính xác và mạnh mẽ hơn bằng cách xử lý hiệu quả dữ liệu nhiều chiều.
Các chức năng mới cho ngày và giờ
Stata 17 bao gồm một loạt các chức năng mới để làm việc với ngày và giờ, giúp thao tác và phân tích dữ liệu liên quan đến thời gian dễ dàng hơn. Các hàm này cho phép người dùng trích xuất các thành phần từ ngày và giờ, tính toán khoảng thời gian, tạo các biến chuỗi thời gian và thực hiện nhiều thao tác khác.
Với các chức năng ngày và giờ nâng cao trong Stata, người dùng có thể xử lý dữ liệu thời gian một cách hiệu quả và rút ra những hiểu biết có ý nghĩa từ các phân tích của họ.
Phân tích tổng hợp rời đi một lần
Phân tích tổng hợp loại bỏ một lần là một kỹ thuật có giá trị để đánh giá mức độ mạnh mẽ và ảnh hưởng của các nghiên cứu riêng lẻ đối với ước tính phân tích tổng thể tổng thể.
Stata 17 giới thiệu các khả năng phân tích tổng hợp loại trừ một lần, cho phép người dùng đánh giá một cách có hệ thống tác động của việc loại trừ từng nghiên cứu khỏi phân tích tổng hợp. Tính năng này cung cấp cho các nhà nghiên cứu sự hiểu biết toàn diện hơn về độ nhạy và tính ổn định của các kết quả phân tích tổng hợp của họ.
Galbraith
Biểu đồ Galbraith, còn được gọi là biểu đồ xuyên tâm hoặc biểu đồ độ lệch hướng tâm, là công cụ đồ họa được sử dụng để đánh giá tính không đồng nhất và xác định các nghiên cứu có ảnh hưởng trong phân tích tổng hợp. Stata 17 kết hợp các biểu đồ Galbraith như một trợ giúp trực quan cho các nghiên cứu phân tích tổng hợp.
Những biểu đồ này cho phép các nhà nghiên cứu xác định trực quan các nghiên cứu có đóng góp lớn cho tính không đồng nhất hoặc các nghiên cứu có quy mô ảnh hưởng cực lớn. Bằng cách cung cấp một cái nhìn tổng quan toàn diện về các kết quả phân tích tổng hợp, sơ đồ Galbraith tạo điều kiện thuận lợi cho việc đưa ra quyết định sáng suốt và giải thích các kết quả phân tích tổng hợp.
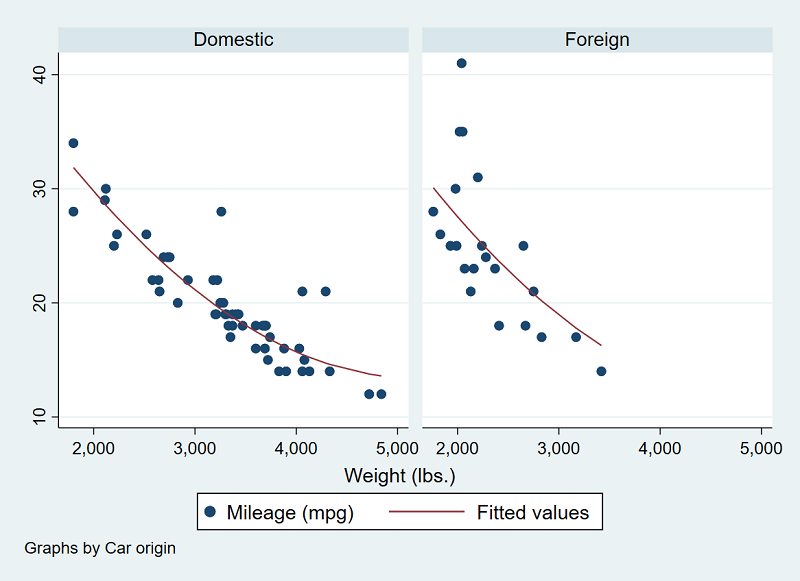
Mô hình logit đa thức dữ liệu bảng điều khiển
Dữ liệu bảng, còn được gọi là dữ liệu đo lường theo chiều dọc hoặc lặp lại, chứa các quan sát về cùng một cá nhân hoặc thực thể trong nhiều khoảng thời gian. Stata 17 giới thiệu các mô hình logit đa thức dữ liệu bảng, cho phép các nhà nghiên cứu phân tích kết quả phân loại với dữ liệu bảng.
Các mô hình này cho phép ước tính tác động của các đồng biến đối với xác suất của các kết quả phân loại khác nhau, tính đến tính không đồng nhất của từng cá nhân cụ thể và các tác động thay đổi theo thời gian. Sự bổ sung này mở rộng phạm vi của các kỹ thuật lập mô hình dữ liệu bảng có sẵn trong Stata, cung cấp cho các nhà nghiên cứu các công cụ toàn diện hơn để phân tích dữ liệu theo chiều dọc.
Tải ngay tại: https://drive.google.com/file/d/1os6o4whJ1Iwvik0PvYxKI46RwjOSJFSZ/view?usp=sharing
Bayesian Panel-Data Models
Stata 17 nâng cao khả năng lập mô hình dữ liệu bảng của nó bằng cách giới thiệu các mô hình dữ liệu bảng Bayesian. Các mô hình dữ liệu bảng Bayes kết hợp các ưu điểm của phân tích dữ liệu bảng với suy luận Bayes, cho phép đưa vào thông tin trước đó và ước tính độ không đảm bảo trong các tham số mô hình. Các mô hình này đặc biệt hữu ích khi xử lý các cỡ mẫu nhỏ, dữ liệu bảng không cân bằng hoặc khi có kiến thức sẵn có. Các mô hình dữ liệu bảng Bayesian cung cấp cho các nhà nghiên cứu một cách tiếp cận linh hoạt và mạnh mẽ để phân tích dữ liệu theo chiều dọc.
Các mô hình logit có thứ tự tăng cao
Các mô hình logit có thứ tự thổi phồng bằng 0 được sử dụng rộng rãi trong nhiều lĩnh vực khác nhau, bao gồm chăm sóc sức khỏe, kinh tế và tâm lý học, để phân tích các kết quả phân loại có thứ tự với các số 0 dư thừa. Stata 17 giới thiệu các mô hình logit có thứ tự thổi phồng bằng 0, cho phép các nhà nghiên cứu tính toán các số 0 dư thừa và ước tính tác động của các đồng biến đối với biến kết quả có thứ tự. Các mô hình này cung cấp phân tích dữ liệu chính xác và toàn diện hơn với các số 0 dư thừa, giúp hiểu sâu hơn về các quy trình cơ bản và các yếu tố quyết định kết quả.
Kiểm tra phi tham số cho xu hướng
Stata 17 giới thiệu các kiểm định phi tham số cho xu hướng, cho phép các nhà nghiên cứu đánh giá các xu hướng trong kết quả thứ tự hoặc liên tục mà không cần giả định một dạng hàm cụ thể. Các thử nghiệm này đặc biệt hữu ích khi phân tích dữ liệu với các kết quả được sắp xếp theo thứ tự hoặc các biến liên tục trong đó mối quan hệ với một biến độc lập không phải là tuyến tính. Các thử nghiệm phi tham số cho xu hướng cung cấp một cách tiếp cận linh hoạt và mạnh mẽ để đánh giá các xu hướng, đảm bảo suy luận chính xác ngay cả khi không có giả định phân phối mạnh.
Phân tích chức năng phản hồi xung Bayesian (IRF) và phân tích phương sai sai số dự báo (FEVD)
Phân tích hàm phản hồi xung (IRF) và phân tích phương sai sai số dự báo (FEVD) là những công cụ cơ bản trong phân tích chuỗi thời gian. Stata 17 giới thiệu phân tích Bayesian IRF và FEVD, cho phép các nhà nghiên cứu điều tra mối quan hệ động giữa các biến và đánh giá sự đóng góp của các cú sốc khác nhau vào phương sai sai số dự báo. Bằng cách kết hợp các phương pháp Bayes, tính năng này cung cấp các ước tính đáng tin cậy hơn và các phép đo độ không đảm bảo so với các phương pháp tiếp cận thường xuyên truyền thống. Phân tích Bayesian IRF và FEVD nâng cao hiểu biết về dữ liệu chuỗi thời gian phức tạp và cho phép các nhà nghiên cứu đưa ra dự đoán chính xác hơn.
Lasso với dữ liệu được nhóm
Dữ liệu được phân cụm, trong đó các quan sát trong cùng một cụm có mối tương quan với nhau, thường gặp trong các lĩnh vực nghiên cứu khác nhau. Stata 17 giới thiệu ước tính bằng dây thòng lọng với dữ liệu được phân cụm, cho phép các nhà nghiên cứu thực hiện lựa chọn và ước tính biến khi có phân cụm. Lasso là một kỹ thuật chính quy hóa tự động chọn các biến có liên quan trong khi thu hẹp hệ số của các biến ít quan trọng hơn. Bằng cách mở rộng ước tính bằng dây thòng lọng sang dữ liệu được phân cụm, Stata 17 cung cấp một công cụ mạnh mẽ để phân tích các tập dữ liệu phức tạp với cấu trúc được phân cụm.
Các mô hình DSGE tuyến tính và phi tuyến Bayesian
Các mô hình Cân bằng chung ngẫu nhiên động (DSGE) được sử dụng rộng rãi trong kinh tế vĩ mô để phân tích sự tương tác giữa các biến số kinh tế khác nhau theo thời gian. Stata 17 giới thiệu các mô hình DSGE tuyến tính và phi tuyến Bayesian, cung cấp một khuôn khổ toàn diện để phân tích động lực học của các hệ thống kinh tế phức tạp.
Các phương pháp Bayes cho phép kết hợp thông tin trước đó, ước tính độ không đảm bảo và xử lý các điểm phi tuyến, nâng cao độ tin cậy và tính linh hoạt của phân tích mô hình DSGE. Những khả năng lập mô hình tiên tiến này cho phép các nhà nghiên cứu hiểu sâu hơn về các cơ chế thúc đẩy các hiện tượng kinh tế vĩ mô.
Các cải tiến của Do-File Editor
Do-File Editor trong Stata 17 đã trải qua những cải tiến đáng kể để cải thiện trải nghiệm mã hóa và hợp lý hóa quy trình làm việc. Trình chỉnh sửa được cập nhật cung cấp giao diện trực quan và thân thiện hơn với các tính năng như tô sáng cú pháp, gấp mã, tự động thụt lề và kiểm tra lỗi được cải thiện. Những cải tiến này làm cho việc viết, sửa lỗi và quản lý tệp do trở nên dễ dàng hơn, tiết kiệm thời gian và công sức cho người dùng Stata.
Stata trên Apple Silicon
Stata 17 hiện hoàn toàn tương thích với Apple Silicon, kiến trúc dựa trên ARM mới được sử dụng trong thế hệ máy tính Mac mới nhất của Apple. Với khả năng tương thích này, người dùng Stata có thể tận dụng tối đa các lợi ích về hiệu suất và hiệu quả do Apple Silicon mang lại.
Cho dù bạn đang chạy Stata trên MacBook Air, MacBook Pro hay Mac mini với Apple Silicon, bạn đều có thể mong đợi hiệu suất liền mạch và sử dụng tài nguyên được tối ưu hóa.
Thư viện hạt nhân toán học Intel (MKL)
Stata 17 kết hợp Intel Math Kernel Library (MKL), một thư viện toán học được tối ưu hóa cao giúp cải thiện hiệu suất của các phép toán số khác nhau. Việc tích hợp MKL nâng cao tốc độ và hiệu quả tính toán số của Stata, dẫn đến thời gian thực hiện nhanh hơn cho nhiều quy trình thống kê. Cho dù bạn đang tiến hành các hoạt động ma trận, hồi quy tuyến tính hay phân tách ma trận, việc sử dụng MKL của Stata 17 đảm bảo hiệu suất và độ chính xác tối ưu.
Tích hợp Java
Stata 17 giới thiệu tích hợp Java nâng cao, cho phép người dùng kết hợp liền mạch mã Java vào quy trình công việc Stata của họ. Sự tích hợp này mở ra một thế giới khả năng, cho phép người dùng tận dụng các thư viện và chức năng mở rộng có sẵn trong Java.
Cho dù bạn cần kết nối với cơ sở dữ liệu bên ngoài, thực hiện thao tác dữ liệu nâng cao hay triển khai các thuật toán tùy chỉnh, tích hợp Java của Stata cung cấp tính linh hoạt và khả năng mở rộng cần thiết cho các tác vụ phân tích phức tạp.
Tích hợp H2O
H2O là một nền tảng máy học mã nguồn mở phổ biến cung cấp nhiều loại thuật toán và công cụ để phân tích dữ liệu. Stata 17 tích hợp với H2O, cho phép người dùng tận dụng sức mạnh khả năng học máy của H2O trực tiếp trong Stata.
Với sự tích hợp này, bạn có thể dễ dàng xử lý trước dữ liệu, xây dựng các mô hình dự đoán và thực hiện các phân tích nâng cao bằng các thuật toán tiên tiến nhất của H2O. Sự tích hợp liền mạch giữa Stata và H2O nâng cao khả năng phân tích của cả hai nền tảng, trao quyền cho các nhà nghiên cứu giải quyết các nhiệm vụ phân tích dữ liệu phức tạp một cách dễ dàng.
Phần kết luận
Stata 17 mang đến một loạt các tính năng và cải tiến mới đáp ứng nhu cầu phát triển của các nhà phân tích và nghiên cứu dữ liệu. Từ các bảng có thể tùy chỉnh đến kinh tế lượng Bayes nâng cao, Stata 17 trao quyền cho người dùng phân tích dữ liệu hiệu quả hơn, đưa ra các suy luận mạnh mẽ và truyền đạt kết quả một cách rõ ràng. Cho dù bạn đang làm việc với các tập dữ liệu lớn, tiến hành phân tích phức tạp hay khám phá các kỹ thuật thống kê tiên tiến, Stata 17 cung cấp các công cụ và khả năng để nâng nghiên cứu của bạn lên một tầm cao mới.
Trên đây là những thông tin cập nhập mới về phần mềm, Techcare hy vọng có thể giúp ích đến cho người đọc. Chúc các bạn thành công.












